在进行网络爬虫登录时,通常会遇到验证码,需要输入用户名和密码。此时,我们就需要使用今天要介绍的Python第三方库ddddocr。ddddocr是一款强大的通用开源OCR识别库,具有高效、准确、易用的特点,广泛应用于图像处理和文字识别任务。本文将为大家介绍ddddocr的基本使用方法和示例代码。
一、背景介绍
在计算机视觉和图像处理领域,数字识别是一个常见的任务,用于从图像中提取数字并进行识别。传统的数字识别算法在单个数字或多位数字的识别上表现良好,但对于双重数字(两位数字)的准确识别却面临一些挑战。为了解决双重数字识别的问题,ddddocr项目应运而生。该项目通过使用深度学习的方法,结合卷积神经网络(CNN)和循环神经网络(RNN),对双重数字进行高效准确的识别。
ddddocr的特点和优势包括:
- 深度学习:ddddocr利用深度学习技术,特别是卷积神经网络和循环神经网络,对双重数字进行准确的识别。
- 开源项目:ddddocr是一个开源项目,允许用户免费使用、修改和分发代码。
- 高准确率:通过深度学习的方法,ddddocr在双重数字识别任务上能够取得较高的准确率。
- 灵活性:ddddocr提供了训练和预测的功能,用户可以根据自己的需求自定义模型并进行训练,以适应不同的双重数字识别任务。
二、安装
直接使用pip安装即可:
pip install ddddocr安装完成后就可以在Python代码中引入ddddocr库了:
import ddddocr三、使用示例
-
识别英文数字验证码


代码示例:
# test.py import ddddocr ocr = ddddocr.DdddOcr(show_ad=False) # show_ad=False关闭广告 with open("./img/1.jpg", "rb") as f1: im = f1.read() yzm1 = ocr.classification(im) with open("./img/2.jpg", "rb") as f2: im = f2.read() yzm2 = ocr.classification(im) print(yzm1, yzm2)运行结果:

-
识别滑块验证码


代码示例:
# test.py import ddddocr det = ddddocr.DdddOcr(det=False, ocr=False, show_ad=False) # show_ad=False关闭广告 with open('img/target.png', 'rb') as f: target_bytes = f.read() with open('img/background.jpg', 'rb') as f: background_bytes = f.read() res = det.slide_match(target_bytes, background_bytes, simple_target=True) print(res)运行结果:

一般只会用到
res['target'][0],这个就是滑块需要滑动的距离。在实际应用中每个网站可能会有偏差,所以要对滑块轨迹进行微调,可以根据网站的滑块和背景图的大小对res['target'][0]进行加减。 -
识别中文点选验证码

代码示例:
# test.py import ddddocr import cv2 det = ddddocr.DdddOcr(det=True, show_ad=False) # show_ad=False关闭广告 with open("./img/dianxuan.jpg", 'rb') as f: image = f.read() poses = det.detection(image) print(poses) im = cv2.imread("./img/dianxuan.jpg") for box in poses: x1, y1, x2, y2 = box im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2) cv2.imwrite("./img/result.jpg", im)运行结果:
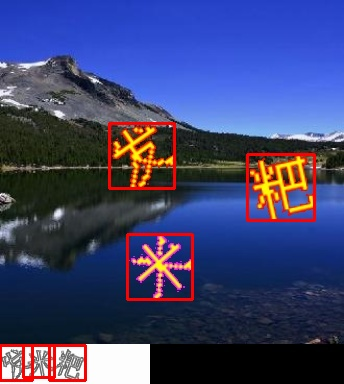
四、总结
本文介绍了使用ddddocr识别英文数字验证码、滑块验证码和中文点选验证码的过程。ddddocr在对图片不进行任何处理的情况下识别效率已经非常高了。在实际应用场景中,我们还可以根据自身需求对图片进行进一步的处理提高识别率。在遇到一些复杂难以识别的验证码时,我们可以对其进行深度学习训练。此外,ddddocr里面还有很多值得学习的东西,有兴趣的小伙伴可以自行研究。











