一、Kubernetes 中 Pod 调度的重要性
在 Kubernetes 的世界里,Pod 调度就像是一个繁忙的交通指挥官,负责把小车(也就是我们的 Pod)送到最合适的停车位(节点)。调度不仅关乎资源的合理利用,还关乎应用的“生死存亡”,下面让我们来看看为什么调度这么重要。
-
资源优化 : 想象一下,如果每辆小车都随意停放,那简直是停车场的灾难!调度器通过精确的“停车导航”,确保每个 Pod 找到合适的停车位,最大化利用资源,避免“挤得满满当当”。
-
故障恢复 : 假设某个节点出故障了,就像一辆车突然抛锚。调度器会迅速反应,把出问题的 Pod 送到其他健康的节点,确保你的应用不至于“趴窝”。
-
负载均衡 : 想象一下,如果所有车都停在同一边,另一边却空荡荡的,那就会造成交通堵塞。调度器会聪明地把 Pod 分散到各个节点,保持负载均匀,就像一个和谐的舞蹈。
-
策略实施 : Kubernetes 调度器可不止是个简单的指挥官,它还有一套自己的“调度法则”。通过亲和、反亲和、污点和容忍等机制,调度器确保每个 Pod 都能按照自己的“喜好”找到理想的驻地,确保万无一失。
-
可扩展性 : 当你的应用像气球一样迅速膨胀,调度器的灵活性就显得尤为重要。它可以轻松应对负载的变化,动态扩展和收缩,确保一切运转顺利。
总之,Pod 调度在 Kubernetes 中就像是后台默默工作的英雄,保证了应用的高效、安全和稳定。了解调度机制,能让你在这个容器化的世界里游刃有余,简直是必备技能!
转载请在文章开头注明原文地址:https://www.cnblogs.com/Sunzz/p/18451805
二、Node Selector
定义与用法
Node Selector,就像是一位细心的“挑剔”朋友,专门帮你选择最合适的聚会场地。在Kubernetes中,Node Selector用来告诉调度器,某个Pod需要在特定的节点上运行。通过这种方式,你可以确保你的应用在最合适的环境中“发光发热”。
想象一下,你的应用是一位超级明星,它希望在拥有高性能显卡的节点上演出,而不是在一个配置较低的机器上“打酱油”。Node Selector正是为了满足这种需求,让你的Pod在适合它们的舞台上展现才华。
示例
假设你有一个需要强大磁盘io能力的应用,想把它放在一个“磁盘大咖”的节点上。
给节点设置标签
先来给node01设置一个disk=ssd的label
kubectl label nodes k8s-node01.local disktype=ssd查看一下标签
kubectl get nodes -l disktype=ssd
NAME STATUS ROLES AGE VERSION
k8s-node01.local Ready <none> 161d v1.30.0
然后使用Node Selector来指定节点的标签。例如:
# node-selector.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2 # 设置 Pod 副本数为 2
selector:
matchLabels:
app: nginx
tEMPlate:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80
nodeSelector:
disktype: ssd创建deployment
kubectl apply -f node-selector.yaml
deployment.apps/nginx-deployment created
kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-56f59878c8-cgfsx 1/1 Running 0 8s 10.244.1.32 k8s-node01.local <none> <none>
nginx-deployment-56f59878c8-z64rz 1/1 Running 0 8s 10.244.1.31 k8s-node01.local <none> <none>
在这个例子中,Pod会被调度到一个标签为
disktype: ssd
的节点上。这样,你的超级明星就可以在最佳环境中大放异彩,而不是在普通的节点上苦苦挣扎!
所以,Node Selector就是你的“挑剔朋友”,帮助你的Pod找到最合适的“舞台”,确保它们能够充分发挥潜力。
三、亲和与反亲和
1. 亲和(Affinity)
定义
亲和,听起来像个恋爱中的小年轻,其实它是 Kubernetes 中帮助你选择 Pod 在哪个节点上“约会”的小助手。通过亲和规则,Pod 可以被调度到具有特定标签的节点上,就像在选择一个合适的地方约会一样!
类型
1. 节点亲和(Node Affinity) :
就像在大城市里找适合自己的房子一样,节点亲和让你可以将 Pod 调度到具有特定标签的节点上。比如,你可能想把 Pod 安排在 SSD 硬盘的节点上,因为那儿的性能更好。
2. Pod 亲和(Pod Affinity) :
如果你想让某些 Pod 在一起生活,互相照应,Pod 亲和就派上用场了。它允许你把新的 Pod 调度到已经存在某个 Pod 的节点上,形成一个“温暖的大家庭”。
示例
下面是一个部署 Nginx 的 YAML 文件,使用节点亲和来确保 Pod 在带有
disktype=ssd
标签的节点上运行:
# affinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTeRMS:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80创建deployment
kubectl apply -f affinity.yaml
deployment.apps/nginx-deployment created
kubectl get pods -l app=nginx -o wide

可以看到都运行在node01的节点上。
反亲和(Anti-affinity)
定义
反亲和是 Kubernetes 中的另一种调度规则,它的目标是避免将 Pod 调度到与某些特定 Pod 相同的节点上。这就像在选择朋友时,某些人你就是不想和他们一起住,即使他们的房子很漂亮。
用途
反亲和通常用于提高应用程序的可用性和容错性。比如,如果你有多个副本的 Pod,而它们都运行在同一个节点上,那么这个节点出问题时,所有副本都会受到影响。反亲和可以确保它们分布在不同的节点上,就像把鸡蛋放在不同的篮子里,以免一篮子摔了,鸡蛋全没了。
示例
下面是一个使用反亲和规则的 YAML 文件,确保 Nginx Pod 不会与已经存在的 Nginx Pod 一起运行:
# anti-affinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80创建deployment
kubectl apply -f anti-affinity.yaml创建后结果如下图所示
kubectl get po -l app=nginx -o wide

可以看到已经有两个pod在运行,分别以node01和node02上,另一个处于peding中。
查看一下为何处于pending中
kubectl describe pod nginx-deployment-5675f7647f-vgkrl kubectl describe pod nginx-deployment-5675f7647f-vgkrl
Name: nginx-deployment-5675f7647f-vgkrl
Namespace: default
Priority: 0
Service Account: default
Node: <none>
Labels: app=nginx
pod-template-hash=5675f7647f
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/nginx-deployment-5675f7647f
Containers:
nginx-container:
Image: nginx:latest
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts:
/var/run/Secrets/kubernetes.io/serviceaccount from kube-api-access-qwjc2 (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
kube-api-access-qwjc2:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMaPOPtional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 2m7s default-scheduler
0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-Plan+e: },
2 node(s) didn't match pod anti-affinity rules.
preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling,
2 No preemption victims found for incoming pod.

可以看到最后边的信息,说明没有可用的节点。
转载请在文章开头注明原文地址:https://www.cnblogs.com/Sunzz/p/18451805
总结
通过亲和与反亲和,Kubernetes 可以根据你的需求,精确调度 Pod,就像一位优秀的派对策划者,确保每个 Pod 在合适的节点上“社交”。这不仅提高了资源利用率,还增强了应用的稳定性。下次部署时,别忘了这些小秘密哦!
四、污点与容忍:如何让你的 Pod 不那么“娇气”
污点(Taints)
定义与用途
污点,就像一块“禁止进入”的牌子,告诉某些 Pod:“嘿,别过来,我不想跟你玩!” 它的作用就是让 Kubernetes 中的节点标记出特殊要求,只有“合适”的 Pod 才能在那里运行。
比如,你有一个超强的节点,需要做一些高强度的计算任务,那你就可以给这个节点加个“污点”,这样普通的 Pod 就不会误闯进来占用资源了。
示例
kubectl taint nodes k8s-node01.local key=value:NoSchedule
在这个例子中,我们给节点
k8s-node01.local
添加了一个叫做
key=value
的污点,并设置为
NoSchedule
。这意味着,除非 Pod 具备容忍这个污点的“超级能力”,否则 Kubernetes 不会调度任何 Pod 到这个节点上。
来创建deployment测试一下看还会不会调度到node01上去
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80创建deployment
kubectl apply -f deployment.yaml 查看pod信息
kubectl get pods -l app=nginx -o wide

可以看到pod都运行在node02上,符合预期,说明污点生效了,默认是不会往node01去调度的。
容忍(Tolerations)
定义与用途
容忍就是 Pod 的“通行证”,让它可以无视节点上的“禁止进入”标志(污点)。Pod 如果想进驻被“污点”标记的节点,就必须带上这个“通行证”才行。这就像是:有些节点很挑剔,但有的 Pod 很“宽容”,它说:“没关系,我能忍。”
如何配合污点使用
容忍的作用就是让 Pod 在被打了污点的节点上仍然能够正常调度。这两者就像是门卫和 VIP 卡的关系——门卫不让随便人进,但有 VIP 卡的 Pod 可以说:“我有容忍力,我能过!”
示例:
# tolerations-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80解释:
-
apiVersion
:
apps/v1表示我们创建的是Deployment资源,Kubernetes 中的Deployment用于管理应用的副本集(即多个 Pod)。 -
replicas
: 定义了我们希望创建的
nginxPod 的副本数量,这里我们设置为2,因此会有两个nginxPod。 -
selector
:
matchLabels通过app: nginx标签选择需要管理的 Pod。 - template : 定义了要部署的 Pod 模板,包括容忍设置和容器规范。
-
tolerations
: 配置了这个
nginxDeployment 的 Pod 可以容忍有特定key=value:NoSchedule污点的节点,允许它们被调度到带有该污点的节点上。 -
containers
: Pod 内的容器,这里使用
nginx:latest镜像,并暴露端口 80。
这个配置部署了两个
nginx
Pod,并且允许它们被调度到有特定污点的节点上(根据配置的
tolerations
)。
创建deployment
kubectl get po -l app=nginx -o wide

这个示例 Pod 中的
tolerations
配置,允许它无视
key=value:NoSchedule
这样的污点,顺利地跑到有“污点”的节点上。
污点与容忍,谁才是调度的老大?
总结一下,污点是节点上的“门禁”,防止无关 Pod 来捣乱,而容忍就是 Pod 的“VIP 卡”,让它无视门禁,照样可以顺利进驻。这两者相辅相成,是 Kubernetes 调度机制中不可或缺的一部分。
有了这些设置,你就可以有效地控制哪些 Pod 能够运行在哪些节点上。记住:带上“通行证”,你就不怕节点的“臭脾气”了!
转载请在文章开头注明原文地址:https://www.cnblogs.com/Sunzz/p/18451805
五、优先级与抢占:Kubernetes 的「大佬」调度策略
在 Kubernetes 世界中,Pod 不再是平等的。是的,Pod 也有「大佬」和「小透明」之分!这一切全靠优先级(Priority)和抢占(Preemption)来决定。让我们一起看看这两位神秘力量如何影响 Pod 的命运吧!
优先级(Priority): 谁是大佬?
定义 :
优先级就是给 Pod 排座次的机制。Kubernetes 允许你给每个 Pod 设定一个「重要程度」,这个重要程度就决定了它在资源紧张时,是被优先照顾,还是默默无闻地排队。
如何设置 :
我们需要先定义一个
PriorityClass
,然后在 Nginx 的
Deployment
里引用它。就像是给 Nginx 发了一张“贵宾卡”。
# priority.yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000
globalDefault: false
description: "High priority for important Nginx pods."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
priorityClassName: high-priority
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
解释: 我们创建了一个名为
high-priority
的优先级类,给它赋值 1000,然后用这个优先级类部署了两个 Nginx Pod。这意味着这些 Nginx Pod 在资源调度上会得到特别的优待,资源紧张时它们会优先被分配。
创建deployment
kubectl apply -f priority.yaml 查看pod信息
kubectl get po -l app=nginx -o wide
kubectl describe pod nginx-deployment-646cb6c499-6k864
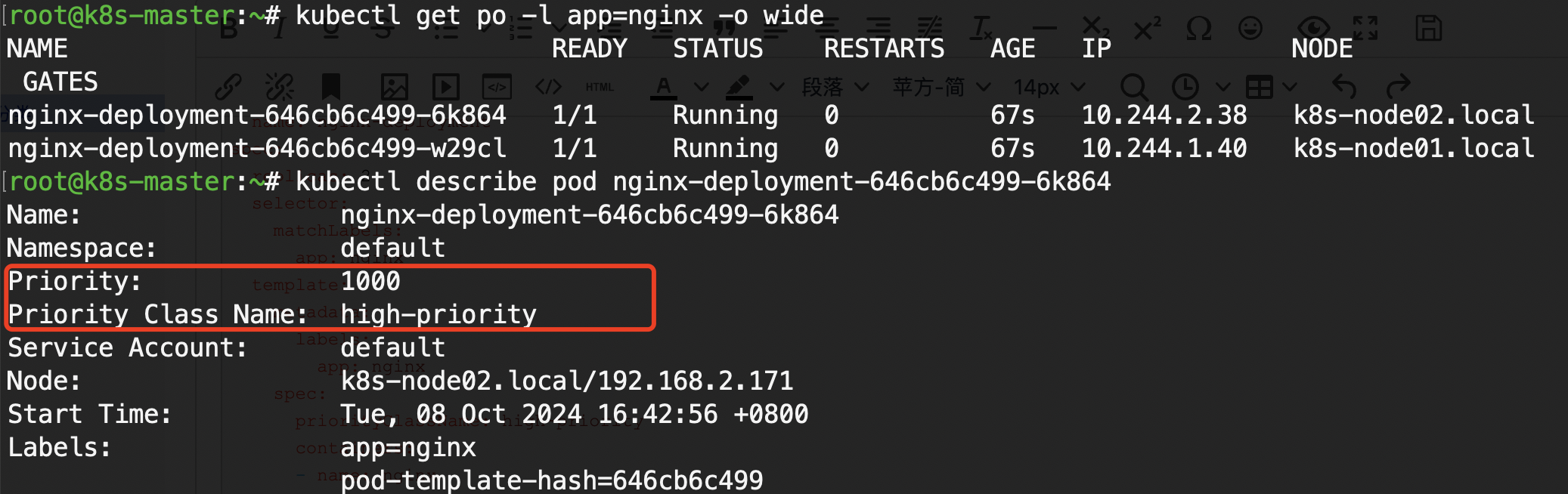
抢占(Preemption):Nginx 也能“赶人”?
定义 : 抢占就像给 Nginx 一个特权,告诉 Kubernetes 如果资源紧张,允许这个高优先级的 Pod 抢占低优先级 Pod 的位置。这样,Nginx 能在关键时刻优雅地“赶走”别人,自己稳稳上场。
示例 :
# preemption.yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: vip-priority
value: 2000
preemptionPolICY: PreemptLowerPriority
globalDefault: false
description: "VIP Nginx pods with preemption power."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment-vip
spec:
replicas: 2
selector:
matchLabels:
app: nginx-vip
template:
metadata:
labels:
app: nginx-vip
spec:
priorityClassName: vip-priority
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
解释
: 这里,我们为
vip-priority
类的 Nginx Pod 赋予了“抢占”特权。如果资源不足,系统会强制“请走”低优先级的 Pod,让 Nginx VIP 顺利登场。
创建
kubectl apply -f preemption.yaml查看pod信息
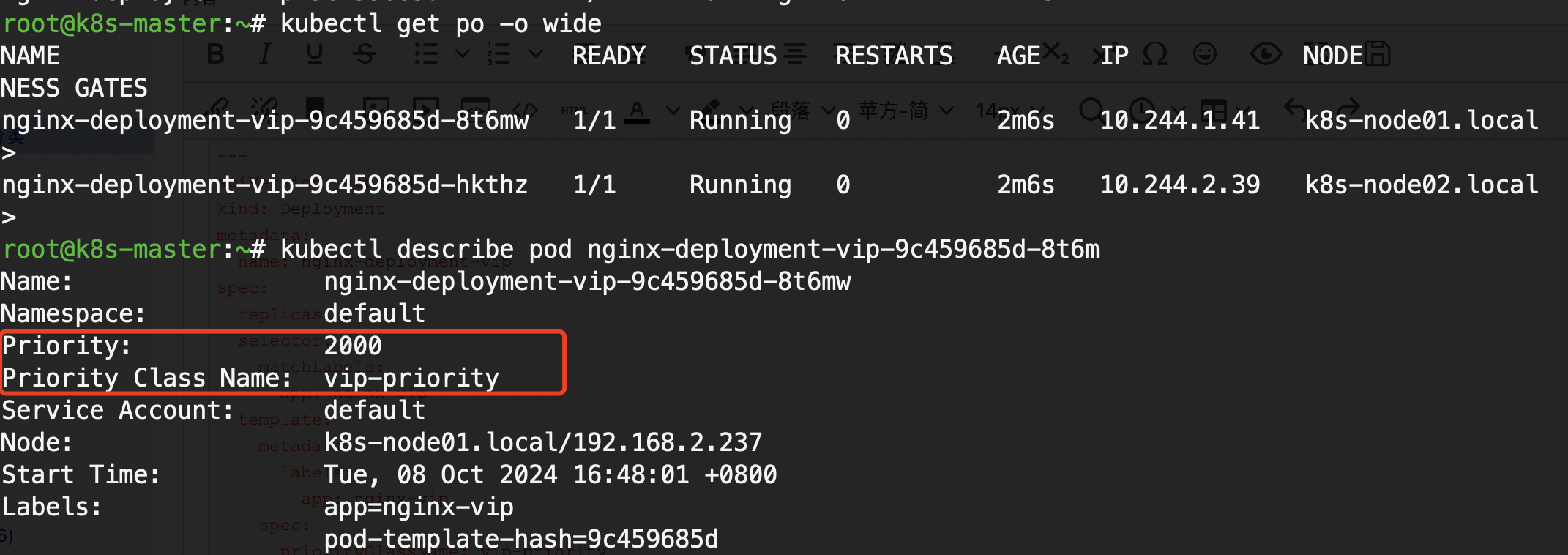
总结:
通过设置优先级,我们可以让某些重要的 Nginx Pod 享有调度特权,而通过抢占,它们甚至能赶走低优先级的 Pod,占据宝贵的资源位。用这种方式,Nginx 不仅能在服务器上跑得快,还能在调度策略上“先发制人”!
六、调度策略:谁来决定 Nginx Pod 住哪里?
Kubernetes 的调度器就是负责给 Pod 找房子的“房屋中介”。它得看哪儿房源充足、住得舒服,同时还得考虑全局平衡。Pod 会被分配到哪台节点上运行,背后其实有一套策略。下面我们来深挖几种常见的调度策略,看看 Nginx Pod 是怎么找到“新家”的。
轮询调度(Round Robin):大家轮着来,公平第一!
通俗解释
:
就像大家吃火锅的时候,食材一轮轮下锅,谁都不会落下。轮询调度按顺序遍历节点,把 Pod 均匀地分配到每个节点上。节点A、B、C都分到活儿,不会让某个节点忙死,而其他节点闲得发霉。
举个例子
:
Nginx Pod 1 给节点A,Pod 2 给节点B,Pod 3 给节点C,下一个再轮到A。
优点
:
简单公平
,特别适合资源相对均衡的情况,能避免某个节点过载。
缺点
:轮着来不等于“聪明地来”,有可能会给那些快要爆满的节点安排更多任务,徒增压力。











