使用Python和Selenium采集动态网页信息的方法
2024-11-01 09:48:02 作者:佚名 --- 好的方法很多,我们先掌握一种 ---
【背景】
对于网页信息的采集,静态页面我们通常都可以通过Python的request.get()库就能获取到整个页面的信息。
但是对于动态生成的网页信息来说,我们通过request.get()是获取不到。
【方法】
可以通过Python第三方库Selenium来配合实现信息获取,采取方案:Python + request + Selenium + BeautifulSoup
我们拿纵横中文网的小说采集举例(注意:请查看网站的robots协议找到可以爬取的内容,所谓盗亦有道):
思路整理:
1. 通过Selenium 定位元素的方式找到小说章节信息
2. 通过BeautifulSoup加工后提取章节标题和对应的各章节的链接信息
3. 通过request + BeautifulSoup 按章节链接提取小说内容,并将内容存储下来
【上代码】
1. 先在开发者工具中,调试定位所需元素对应的xpath命令编写方式
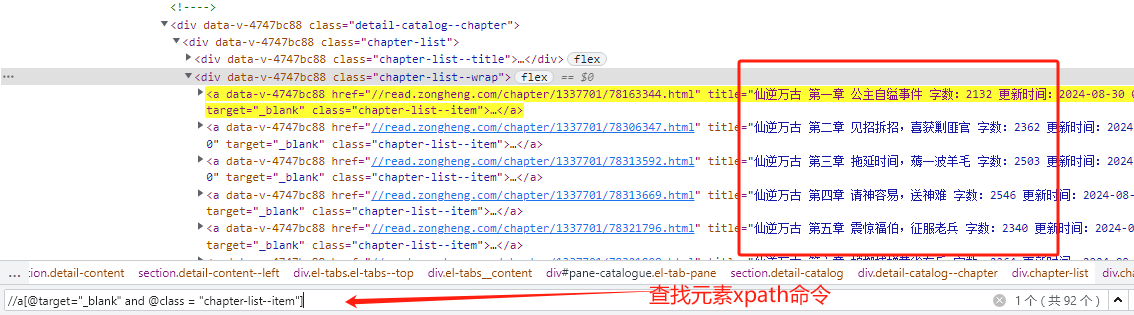
2. 通过Selenium 中find_elements()定位元素的方式找到所有小说章节,我们这里定义一个方法接受参数来使用
3. 把采集到的信息通过BeautifulSoup加工后,提取章节标题和链接内容
4. 通过request + BeautifulSoup 按章节链接提取小说内容,并保存到一个文件中











